In the past two weeks, I’ve been working on the roadmap for the 0.1.0-alpha
release.
gcov
gcov has been fully integrated to measure code coverage with
cpp-coveralls. gcov works by
injecting code during the compilation with gcc.
You can see the coverage on coveralls.io,
it’s updated automatically during the CI build.
Current master branch coverage:
The inconvenient is that since coveralls measures coverage from C sources using
valac generated C code, it is not possible to identify which regions are
covered in Vala. However, it is still possible to identify these regions in the
generated code.
Asynchronous handling of requests
I changed the request handling model to be fully asynchronous.
VSGI.Application handler have become an async function, which means that
every user request will be processed concurrently as the server can immediatly
accept a new request.
Merged glib-application-integration in the trunk
The branch was sufficiently mature to be merged in the trunk.
I will only work on coverage and minor improvements until I reach the second
alpha release.
It brings many improvements:
VSGI.Server inherit from GLib.Application, providing enhancements described in
the Roadmap for 0.1.0-alpha
setup and teardown in the Router for pre and post processing of requests
user documentation improvments (Sphinx + general rewrites)
optional features based on gio-2.0 and libsoup-2.4 versions
0.1.0-alpha released!
I have released a 0.1.0-alpha version. For more information, you can read the
release notes on GitHub,
download it and try it out!
Integration of GLib.Application is really cool. It basically provide any
written application with a GLib.MainLoop to process asynchronous tasks and
signals to handle startup and shutdown events right from the Server.
usingValum;usingVSGI.Soup;varapp=newRouter();varserver=newServer(app);// unique identifier for your applicationapp.set_application_id("your.unique.application.id");app.get("",(req,res)=>{res.write("Hello world!".data);});server.startup.connect(()=>{// no request have been processed yet// initialize services here (eg. database, memcached, ...)});server.shutdown.connect(()=>{// called after the mainloop finished// all requests have been processed});server.run();
Moreover, application can access a DBusConnection and obtain environment data
or request external services.
This sample uses the org.freedesktop.hostname DBus service to obtain
information about the hosting environment. Note that you can use DBus to
perform IPC between workers
fairly easily in Vala.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
varconnection=server.get_dbus_connection();app.get("hostname",(req,res)=>{// asynchronous dbus callconnection.call.begin("org.freedesktop.hostname",// bus name"/org/freedesktop/hostname",// object path"org.freedesktop.hostname",// interface"Hostname",null,// no argumentsVariantType.STRING,// return typeDBusCallFlags.NONE,-1,// timeoutnull,(obj,r)=>{varhostname=connection.call.end(r);res.write(hostname.get_string().data);});});
GLib.Application are designed to be held and released so that it can quit
automatically whenever it’s idle (with a possible timout). Gtk uses it to count
the number of opened windows, we use it to measure the number of processing
requests.
Past a certain timeout after the last release, the worker will terminate.
If you have a long-running operation to process asynchronously that does not
involve writting the response (in which case, you are better blocking), you
have to hold the application to keep it alive while it’s processing.
What next?
The next release will be more substantial:
middlewares
components (if relevant)
improve VSGI specification
more signals to handle external events
better documentation to guide implementations
new VSGI implementations (SCGI & CGI)
extract VSGI (if ready)
I decided to go ahead for a Mustache implementation that targets GLib and
GObject. I’m still surprised that it hasn’t been done yet. It is clearly
essential to bring Vala in general purpose web development. The development
will be in a separate project here on
GitHub and it will not block
the release of the framework.
GResource API is really great and it would be truly amazing to bundle Mustache
templates like we already do with CTPL.
As part of the first week, I have to produce an initial document describing what
I will be working on during the semester. Once it’s written down, I will post it
on this blog.
I have already a good idea of what I would like to work on:
finish VSGI specification
second alpha release & feedback from communities
SCGI implementation
mustache implementation for GLib
more tests and awesomeness
The first alpha release is already 4 years old and this one bring such radical
changes that we’re almost starting over. Therefore, a second alpha release will
permit us to tease the targeted audience and obtain recommendations to build the
very best framework.
SCGI is a very
simple protocol to communicate HTTP messages over streams. It will take a real
advantage of the GIO stream API and
I am sure this could become an efficient way to serve web application in
production.
Mustache (or any templating engine) is essential
if we want to bring Valum outside the web service development. I plan to
provide a GLib implementation so that it can be used anywhere. CTPL will remain
the default templating engine for its simplicity and convenience as it covers
quite well simple UI requirements.
Testing is part of any sane software development process. I will focus on
providing quality software that does not break easily.
Subsequent weeks will contain more sustained posts that will describe what have
been done, so stay put!
I will officially work on Valum this summer under the direction of
François Major
at the IRIC lab.
As part of the evaluation, I will be have the opportunity to demonstrate the
framework potential with an assignment. Also, I am required to keep track of
the project advancements, so keep in touch with the Valum category of
my blog!
I never thought I would find zsh actually that great. I feel like I’ve been
missing a nice prompt since ages.
I would like to cover my first experience a little and show you how you can turn
your default shell into a powerful development tool. In order to do that, you
have to:
install zsh
get a real plugin manager (antigen here!)
get a really nice and powerful prompt
enjoy all the above!
zsh is quite easy to install using your distribution package manager:
ghdl is a great tool to prototype hardware quickly. It can be combined with
gtkwave to analyze signals.
I did hardware design last semester and this is a bit tough for my mind right
now, but I think it could help others out having a hard time with Quartus II.
This post explain how to replace Quartus in the process of developing the device
…
First of all, you need ghdl and gtkwave installed on your workstation.
ghdl can analyze, elaborate or run a simulation. The analyze part is essential
as it will generate object files for each entities. Then you can link all those
into a single executable. This is automated by the make command.
make
Once you have a correct result, you may run it and capture signals
./testbed --vcd=testbed.vcd
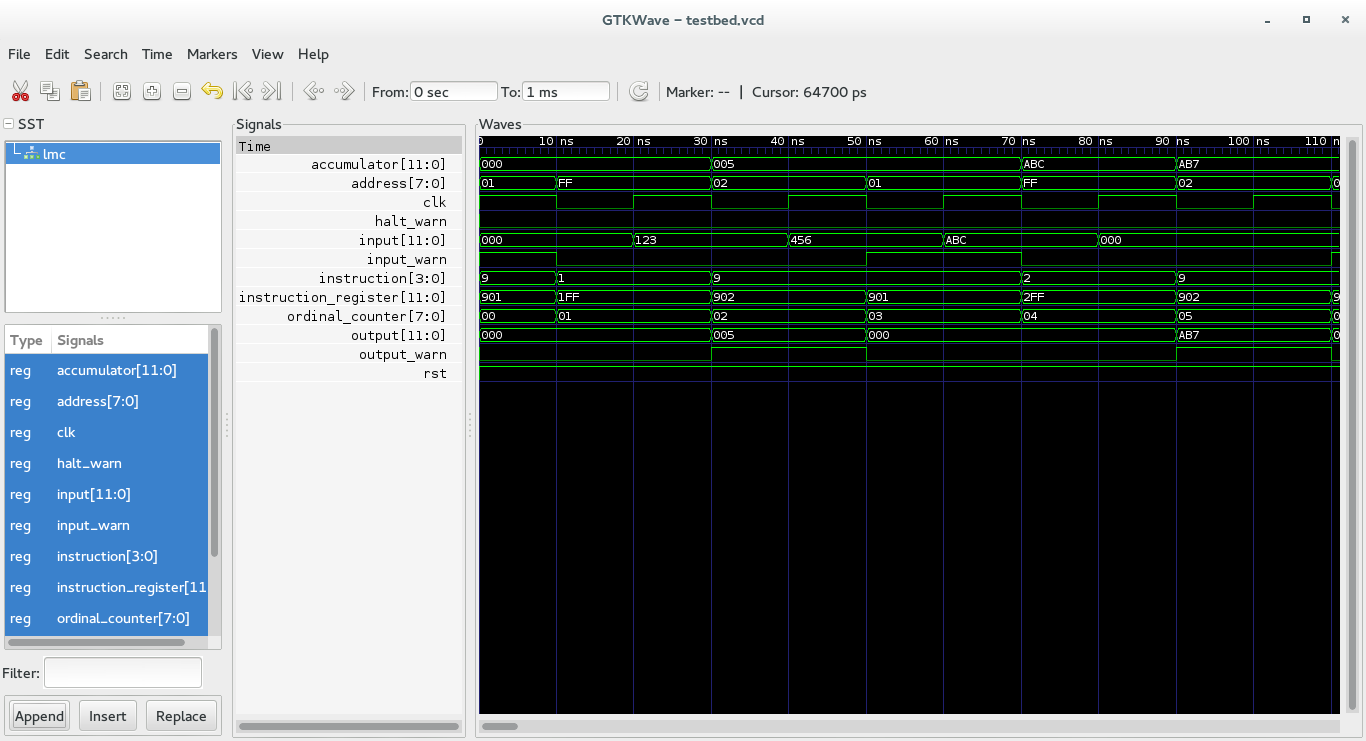
gtkwave is a tool designed to analyze signals, specifically the generated vcd
file.
gtkwave testbed.vcd
In gtkwave, you have to select the device in SST section and append the signals
on your workarea. You may then zoom it and out to see the actual waves.
Example of gtkwave usage.
I really hope this will help you out! I did enjoy VHDL and I really liked
learning Ada-like syntax.
This week-end, I’ll be participating to WearHacks which occurs in my hometown
Montreal. You can find out more here.
So far, I am very confident. We have 2 excellent programmers and a UI/UX guys
which will be working on Unity. If everything goes as planned, we will push a
web app backed with Python offering a very interesting user experience.
I have two concerns right now. I do not know much about the device, which will
be the Nod ring and I am worried about scaling the
computation we will have to be done. Roughly, we have to do some linear algebra
and approximate value comparison.
Thing is, I want to keep stuff in Python as it will allow us to code lightning
quick, which is essential when you have a 36 hours deadline.
Communicating using Bluetooth
That’s the tricky part: we don’t know the device since it’s not on market. We
will have to reverse-engineer the data we need. I know it follows these
OpenSpacial next-to-be standard and it seems to work in 6D (x, y, z) for
acceleration and gyro, so if I can extract that data, I’m fine. I need to do
this quick, if I can do it, then the rest will be a piece of cake.
I will also have the possibility to communicate with people who designed the
hardware, so I guess I will have more information on Bluetooth protocol implied
and general data encoding.
Scaling the computation
We will receive 3-directional data from the device which is pretty much an
accelerometer. We have to figure out the trajectory, smooth the transitions and
compare it with another trajectory. This is a lot of data to treat, especially
since we need to have the result in real time (otherwise, we will have to
redesign the product). I plan to rely on numpy to make
any of these calculation possible.
I will have to normalize the acceleration based on gyroscope data. I do not want
to deal with rotational acceleration.
The trajectory will be approximated using a polynom per dimension since the
acceleration data is 3-dimensional. I will generate a polynom going through
every points of acceleration using the
polyfit
function.
To compare two trajectories, we will have to calculate the integral difference
between each polynoms
Communicating with the frontend
Frontend communication will be done using WebSocket through
socket.io library. It creates a full-duplex communication
system, which will allow us to communicate in both directions. The device will
update the frontend and the frontend will send messages. The frontend uses
Unity, so this library will do the trick
UnitySocketIO.
Producing the UI
UI will be done using Unity 3D. I do not know much about it and I don’t need to!
It has a recipe for installing Kohana files like index.php and application/bootstrap.php
make install
It runs PHPUnit
make test
Or minify your resources
make minify
It is fully configurable, so if you use a different css minifier, you may edit
the file like you need it.
My goal is to provide every Kohana developer with a good Makefile to automate
frequent tasks when using the framework. I will eventually propose it in the
sample Kohana application.
It is a web application offering juridic services for french societies. It allow
creation, modification and liquidation of these legal entities. Its website can
be found here at ruedesjuristes.com.
It’s done entirely in PHP using the Kohana framework.
This was the first time I would be working with Twig. It was a really nice
experience. Development was extremely fast and I would no lie saying it has
never bugged me. I did unit testing with PHPUnit and Kohana Request, which is
surprisingly efficient.
I’ve been a little frustrated with errors handling when I had some mistakes in
my Twig syntax. When you get an error in a parsing tree and your debugger print
humongous structure recursively, you get out of memory quite quickly. To avoid
this, you may reduce the depth of recursion in Debug::dump by overloading
it.
The great thing about Kohana is its cascading file system (CFS), which allow us
to override its default behiaviours.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<?phpdefined('SYSPATH')ordie('No direct script access.');classDebugextendsKohana_Debug{/**
* Reducing the default $depth from 10 to 2 to avoid reaching memory limit.
*/publicstaticfunctiondump($value,$length=128,$depth=2){returnparent::dump($value,$length,$depth);}}
If you work with light templates, you should be fine with the default depth. It
is something to consider only if you reach the memory limit.
JSON really saved me here! The website collects an big amount
of data to proceed the legal formalities. User have to submit forms with around
60 inputs. All the data are serialized once using json_encode. I used the
ORM::filters feature to serialize the data on need.
Form can also be submitted in ajax. To do so, you may use Request::is_ajax
and disable template rendering by setting Request::$auto_render to FALSE.
I usually encode ORM_Validation_Exception errors if anything
wrong happen: they are well structured and translated, so it becomes a charm to
map errors to input!
It is also parsing recipient list using a nice regex, so you do not have to
worry sending more personal mail to your user, even if they have non-ascii
username. It the worst case, it defaults to his email.
Moreover, it supports attachment, so whenever you need to append a legal
document or an alternate message:
Kohana is HMVC, which means that you can request any of your page in the
execution of any internal Request. This is extremly convenient when
testing an application, since it generally ends up being about requesting an
endpoint and asserting the new states of your data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<?phpdefined('SYSPATH')ordie('No direct script access.');classHomeTestextendsUnittest_TestCase{publicfunctiontestIndex(){$response=Request::factory('')->execute();$this->assertEquals(200,$response->status());$this->assertTag(array('tag'=>'h1','content'=>'Hello world!'),$response->body());// ...}
Even the mail module is fully testable using Mail_Sender_Mock. It is a
nice feature that simulates a mailing driver. It speeds up considerably the
testing as you don’t need to wait for Sendmail.
<?phpdefined('SYSPATH')ordie('No direct script access.');classHomeTestextendsUnittest_TestCase{publicfunctiontestMail(){$response=Request::factory('mail')->method(Request::POST)->values(array('email'=>'foo@example.com'))->execute();$mail=array_pop(Mail_Sender_Mock::$history);$this->assertEquals('text/html',$mail->content_type());$this->assertContains('foo@example.com',$mail->to);$this->assertTag(array('tag'=>'h1','content'=>'Hello world!'),$mail->body());// ...}
The website implements a payment solution based on PayPal. I did some work on
a PayPal module I have written, which
has become a simple external Request factory. It is much more convenient
this way then how it was before, since it reuses the code from Kohana.
I also improved the IPN implementation. It was a little buggy, since I never
really used it, but now it is fully working and tested!
Fixtures
Fixtures are really nicely done. I’ve overloaded Unittest_TestCase to add some
on-the-fly ORM generators. For instance, if you need a user to test the
login action:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<?phpdefined('SYSPATH')ordie('No direct script access.');classUnittest_TestCaseextendsKohana_Unittest_TestCase{publicfunctiongetUser(){returnORM::factory('User')->values(array('username'=>uniqid(),'email'=>uniqid().'@ruedesjuristes.com','password'=>'abcd1234'))->add('roles',ORM::factory('Role',array('name'=>'login')));}}
This is much better, in my opinion, than rely on Unittest_Database_TestCase
for an ORM based application.
Coverage
It is also the first time I’ve experienced test coverage and honestly, what an
amazing tool. It pretty much analyze your code while tests are running and
outputs statistics about code complexity and percentage of line execution.
Untested code is likely not to work, so having a good coverage is really
important.
This project shown me tools that made the development considerably faster and
fun. Having not to debug was probably the best thing I’ve experienced so far.
Also, delivering a high quality web app really changed the way I’ve been seeing
the development process.