Valum is a web micro-framework written in the
Vala programming language. It is
a powerful and minimalistic tool build on VSGI, a middleware that supports
multiple HTTP servers and communication protocols.
Valum class diagram can provide you a good idea of
the internal architecture of the framework. It is a SVG generated by
Dia, an good general purpose diagram editor.
To have a better understanding of how VSGI processes a client request, you may
consult the client request processing
UML sequence diagram.
The rewrite of valadoc.org in Vala using Valum has been
completed and should be deployed eventually be elementary OS team (see pull
#40). There’s a couple of interesting stuff there too:
experimental search API using JSON via the /search endpoint
GLruCache now has Vala bindings and an improved API
an eventual GMysql wrapper around the C client API if extracting the classes
I wrote is worth it
In the meantime, you can test it at valadoc2.elementary.io
and report any regression on the pull-request.
Valum 0.3 has been patched and improved while I have been working on the 0.4
feature set. There’s a work-in-progress WebSocket middleware,
VSGI 1.0 and support for PyGObject planned.
If everything goes as planned, I should finish the AJP backend and maybe
consider Lwan.
On the top, there’s Windows support coming, although the most difficult part is
to test it. I might need some help there to setup AppVeyor CI.
I’m aware of the harsh discussions about the state of Vala and whether or not
it will just end into an abysmal void. I would advocate inertia here: the
current state of the language still make it an excelllent candidate for
writing GNOME-related software and this is not expected to change.
The first release candidate for Valum 0.3 has been launched today!
Get it, test it and be the first to find a bug! The final release will
come shortly after along with various Linux distributions packages.
This post review the changes and features that have been introduced since the
0.2. There’s been a lot of work, so take a comfortable seat and brew yourself
a strong coffee.
The most significant change has probably been the introduction of Meson as
a build system and all the new deployment strategy it now makes possible.
If you prefer avoiding a full install, it’s not possible to use it as
a subproject. These are defined as subdirectories of subprojects, which you
can conveniently track using git submodules.
There’s been a lot of new features and I hope I won’t miss any!
There’s a new url_for utility in Router that comes with named route. It
basically allow one to reverse URLs patterns defined with rules and raw paths.
All that is needed is to pass a name to rule, path or any method helper.
I discovered the : notation for named varidic arguments if they alternate
between strings and values. This is typically used to initialize GLib.Object.
usingValum;usingVSGI;varapp=newRouter();app.get("/",(req,res)=>{return"<a href=\"%s\">View profile of %s</a>".printf(app.url_for("user",id:"5"),"John Doe");});app.get("/users/<int:id>",(req,res,next,ctx)=>{varid=ctx["id"].get_string();returnres.expand_utf8("Hello %s!".printf(id));},"user");
In Router, we also have:
asterisk to handle * URI
once for performing initialization
path for a path-based route
rule to replace method
register_type rather than a GLib.HashTable<string, Regex>
Another significant change is that the previous state stack has been replaced
by a context tree with recursive key resolution. It pretty much maps string
to GLib.Value in a non-destructive way.
In terms of new middlewares, you’ll be glad to see all the built-in
functionnalities we now support:
authentication with support for the Basic scheme via authenticate
content negotiation via negotiate, accept and more!
static resource delivery from GLib.File and GLib.Resource bundles
basic to strip the Router responsibilities
subdomain
basepath to prefix URLs
cache_control to set the Cache-Control header
branch on raised status codes
perform work safely and don’t let any error leak!
stream events with stream_events
Now, which one to cover?
The basepath is my personal favourite, because it allow one to create
prefix-agnostic routers.
There’s a lot of stuff happening in each of them so refer to the docs!
Quick review into Request and Response, we now have the following helpers:
lookup_query to fetch a query item and deal with its null case
lookup_cookie and lookup_signed_cookie to fetch a cookie
cookies to get cookies from a request and response
convert to apply a GLib.Converter
append to append a chunk into the response body
expand to write a buffer into the response body
expand_stream to pipe a stream
expand_file to pipe a file
end to end a response properly
tee to tee the response body into an additional stream
All the utilities to write the body come in _bytes and _utf8 variants. The
latter properly set the content charset when appliable.
Back into Server, implementation have been modularized with GLib.Module and
are now dynamically loaded. What used to be a VSGI.<server> namespace now has
become simply Server.new ("<name>"). Implementations are installed in
${prefix}/${libdir}/vsgi-0.3/servers, which can be overwritten by the
VSGI_SERVER_PATH environment variable.
The VSGI specification is not yet 1.0, so please, don’t write a custom server
for now or if you do so, please submit it for inclusion. There’s some
work-in-progress for Lwan and AJP as I speak if you have some time to spend.
Options have been moved into GLib.Object properties and a new listen API
based on GLib.SocketAddress makes it more convenient than ever.
The GLib.Application code has been extracted into the new VSGI.Application
cushion used when calling run. It parses the CLI, set the logger and handle
SIGTERM into a graceful shutdown.
Server can also fork to scale on multicore architectures. I’ve backtracked on
the Worker class to deal with IPC communication, but if anyone is interested
into building a nice clustering system, I would be glad to look into it.
That wraps it up, the rest can be discovered in the updated docs. The API
docs should be available shortly via valadoc.org.
I manage to cover this exhaustively with abidiff, a really nice tool to
diff two ELF files.
Long-term notes
Here’s some long-term notes for things I couldn’t put into this release or that
I plan at a much longer term.
It has to return a type that is derived from VSGI.Server and instantiable
with GLib.Object.new. The Vala compiler will automatically generate the code
to register class and interfaces into the type_module parameter.
Some code from CGI has been moved into VSGI to provide uniform handling of its
environment variables. If the protocol you want complies with that, just
subclass (or directly use) VSGI.CGI.Request and it will perform all the
required initialization.
For more flexibility, servers can be loaded with ServerModule directly,
allowing one to specify an explicit lookup directory and control when the
module should be loaded or unloaded.
The implementation is really simple: one provide a header, a string describing
expecations and a callback invoked with the negotiated representation. If no
expectation is met, a 406 Not Acceptable is raised.
app.get("/",negotiate("Accept","text/xml; application/json",(req,res,next,ctx,content_type)=>{// produce according to 'content_type'}));
Content negotiation is a nice feature of the HTTP protocol allowing a client
and a server to negotiate the representation (eg. content type, language,
encoding) of a resource.
One very nice part allows the user agent to state a preference and the server
to express quality for a given representation. This is done by specifying the
q parameter and the negotiation process attempt to maximize the product of
both values.
The following example express that the XML version is poor quality, which is
typically the case when it’s not the source document. JSON would be favoured –
implicitly q=1 – if the client does not state any particular preference.
Mounted as a top-level middleware, it provide a nice way of setting
a Content-Type: text/html; charset=UTF-8 header and filter out
non-compliant clients.
My up key stopped working, so I’m kind of forced into vim motions.
All warnings have been fixed and I’m looking forward enforcing
--experimental-non-null as well.
The response head is automatically written on disposal and the body is not
closed explicitly when a status is thrown.
In the mean time, I managed to backport write-on-disposal into the
0.2.12 hotfix.
I have written a formal grammar and working on an implementation that will be
used to reverse rules.
VSGI Redesign
There’s some work on a slight redesign of VSGI where we would allow the
ApplicationCallback to return a value. It would simplify the call of a next
continuation:
It will deal with writting the head, piping the passed buffer and close the
response stream properly.
The asynchronous versions are provided if gio (>=2.44) is available during
the build.
SCGI improvements
Everything is not buffered in a single step and resized on need if the request
body happen not to hold in the default 4kiB buffer.
I noticed that set_buffer_size literally allocate and copy over data, so we
avoid that!
I have also worked on some defensive programming to cover more cases of failure
with the SCGI protocol:
encoded lengths are parsed with int64.try_parse, which prevented SEGFAULT
a missing CONTENT_LENGTH environment variable is properly handled
I noticed that SocketListener also listen on IPv6 if available, so the SCGI
implementation has a touch of modernity! This is not available (yet) for
FastCGI.
Right now, I’m working on supporting UNIX domain socket for SCGI and
libsoup-2.4 implementations.
It’s rolling at 6k req/sec behind Lighttpd on my shitty Acer C720, so enjoy!
I have also fixed errors with the FastCGI implementation: it was a kind of
major issue in the Vala language. In fact, it’s not possible to
return a code and throw an exception simultaneously, which led to an
inconsistent return value in OutputStream.write.
To temporairly fix that, I had to supress the error and return -1. I’ll have
to hack this out eventually.
In short, I managed to make VSGI more reliable under heavy load, which is
a very good thing.
I have just backported important fixes from the latest developments in this
hotfix release.
fix blocking accept call
async I/O with FastCGI with UnixInputStream and UnixOutputStream
backlog defaults to 10
The blocking accept call was a real pain to work around, but I finally ended
up with an elegant solution:
use a threaded loop for accepting a new request
delegate the processing into the main context
FastCGI mutiplexes multiple requests on a single connection and thus, it’s hard
to perform efficient asynchronous I/O. The only thing we can do is polling the
unique file descriptor we have and to do it correctly, why not reusing
gio-unix-2.0?
The streams are reimplemented by deriving UnixInputStream and
UnixOutputStream and overriding read and write to write a record instead
of the raw data. That’s it!
I have also been working on SCGI: the netstring processing is now fully
asynchronous. I couldn’t backport it as it was depending on other breaking
changes.
Method.GET actually stands for Method.ONLY_GET | Method.HEAD so that it can
also capture HEAD requests. It’s pretty handy, but I still need to figure out
how to strip the produced body.
Loading of application described as a dynamic module (see
GModule
for more details) will be brought by a small utility named vsgi. It will be
able to spawn instances of the application using a VSGI implementation.
The application has to be written in a specific manner and provide at least one
entry point:
All VSGI implementations are loadable and compatible with GLib.TypeModule.
The application is automatically reloaded on SIGHUP and it should be possible
to implement live reloading with GLib.FileMonitor
to facilitate the development as well as integration of Ivy
to beautify the stack trace.
Multipart I/O Streams
The multipart stream is essential for any web application that would let
clients submit files.
I couldn’t touch the framework much these last days due to my busy schedule, so
I just wanted to write a few words.
I like the approach used by Express.js to branch in
the routing by providing a forward callback and call it if some conditions are
met.
It is used for content negociation and works quite nicely.
app.get("",accept("text/html",(req,res,next)=>{// user agent understands 'text/html'// well, finally, it's not availablenext(req,res);}));app.get("",(req,res)=>{// user agent wants something else});
Other negociator are provided for the charset, encoding and much more. All the
wildcards defined in the HTTP/1.1 specification are understood.
The code for static resource delivery is almost ready. I am finishing some
tests and it should be merged.
It supports the production of the following headers (with flags):
If the resource is not found, next is invoked to dispatch the request to the
next handler.
One last thing is GSequence, which store a sorted sequence in
a binary tree. I think that if we can sort Route objects in some way, this
could provide a really effective routing in logarithmic time.
This last weekly update marks the final release of valum-0.2 and a couple of
things happened since the last beta release:
code and documentation improvements
handle all status codes properly by using the message as a payload
favour read_all over read and write_all over write for stream
operations
all and methods now return the array of created Route objects
move cookies-related utilities back to VSGI
sign and verify for cryptographically secure cookies
filters and converters for Request and Response
I decided to move the cookies-related utilities back into VSGI, considering
that VSGI provide a layer over libsoup-2.4 and cookies utilities are simply
adapting to the Request and Response objects.
I introduced sign and verify to perform cookie signature and verification
using HMAC.
usingSoup;usingVSGI;varcookie=newCookie("name","value",...);cookie.@value=Cookies.sign(cookie,ChecksumType.SHA512,secret);string@value;if(Cookies.verify(cookie.@value,ChecksumType.SHA512,secret,out@value)){// cookie is authentic and value is stored in @value}
The signing process uses a HMAC signature over the name and value of the cookie
to guarantee that we have produced the value and associated it with the name.
the algorithm is chosen from the GChecksumType
enumeration
the secret is chosen
the name and value are from the cookie
The documentation has been updated with the latest changes and some parts were
rewritten for better readability.
Filters and converters
Filters and converters are basis to create filters for Request and Response
objects. They allow a handling middleware to apply composition on these objects
to change their typical behaviour.
Within Valum, it is integrated by passing the Request and Response object
to the NextCallback.
app.get("",(req,res,next)=>{next(req,newBufferedResponse(res));}).then((req,res)=>{// all operations on res are buffered, data are sent when the// stream gets flushedres.write_all("Hello world!".data,null);});
These are just a beginning and the future releases will introduce a wide range
of filters to create flexible pipelines.
Work on Mirdesign testcases
I have been actively working on Mirdesign testcases and finished its API
specification.
final API specification
poll for status update
grammar productions and tokens implementation in JavaScript to generate code
from an AST
The work on grammar productions and tokens in JavaScript will eventually lead
to a compliant implementation of Mirdesign which will be useful if we decide to
go further with the project. The possible outcome would be to provide all the
capabilities of the language in an accessible manner to people in the field.
To easily integrate dependencies, Browserify is used to bundle relevant
npm packages.
store.js to store data in localStorage with multiple fallbacks
codemirror to let user submit its own design
lex to lex a Mirdesign input
numeral to generate well formatted number according to Mirdesign EBNF
fasta-parser to parse a fasta input
I updated the build system to include the JS compilation with Google Closure Compiler
and generation of API documentation with Swagger in the
parallel build. I first thought using another build system specialized in
compiling front-end applications, but waf is alread well adapted for our
needs.
Google Closure Compiler performs static type checking, minification and
generation of highly optimized code. It was essential to ensure type safety for
the use of productions and tokens.
JSDocs is used to produce the documentation for the
productions, tokens as well as the code backing the user interface.
I decoupled the processing function from the ThreadPool as we will eventually
target a cluster using TORQUE
to perform computation.
The 0.2.0-beta has been released with multiple improvements and features that
were described in the preceeding update. It can be
downloaded from GitHub
as usual or installed from the Docker image.
The documentaion has been nicely improved with more contextual notes to put
emphasis on important points.
The framework has reached a really good level of stability and I should
promptly release a stable version in the coming week.
There’s a couple of features I think that could be worth in the stable release:
listen to multiple sources (socket, file descriptor, )
listen to an arbitrary socket using a descriptive URL
I have implemented a lookup function for cookies which finds a cookie in the
request headers by its name.
varcookie=Cookies.lookup("session",req.headers);
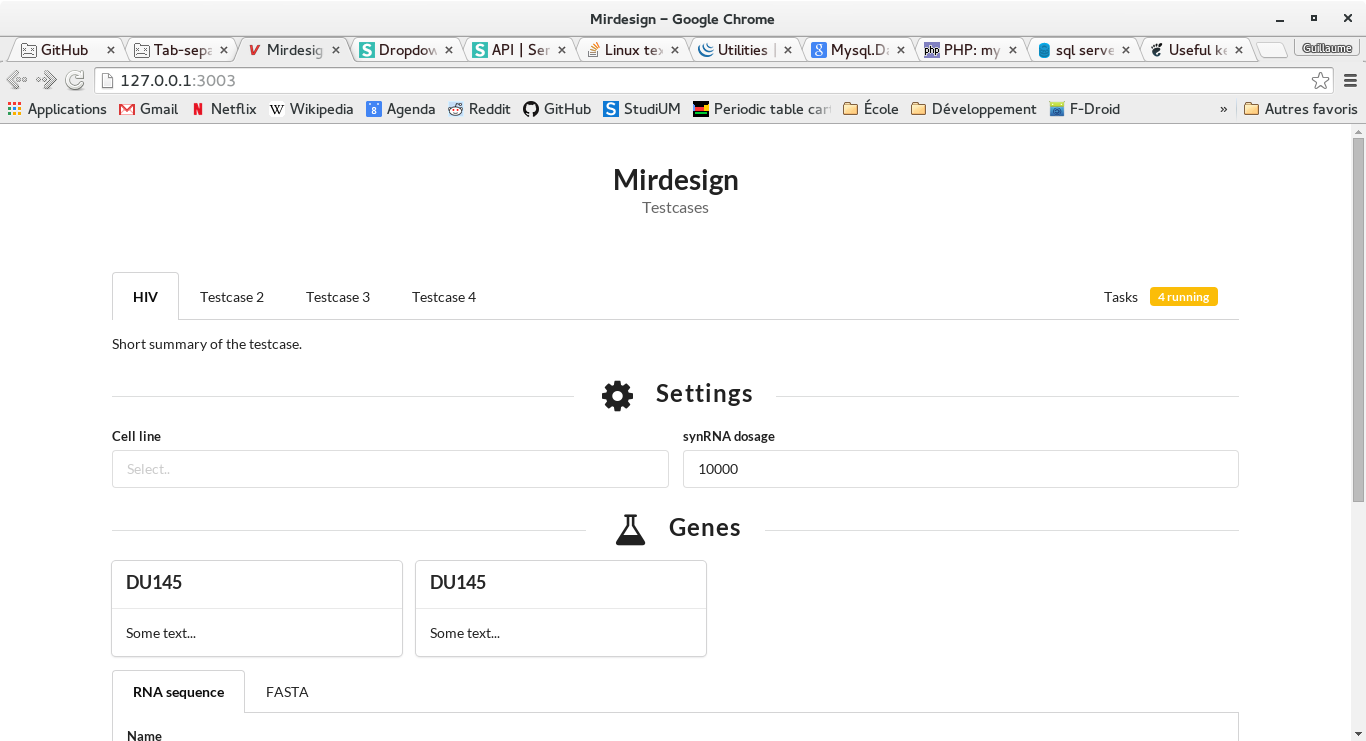
Mirdesign
I started working more seriously on the side project as I could meet up with
Nicolas Scott to discuss what kind of web applications will be developed with
Valum.
Mirdesign HIV prototype built with Semantic UI.
But first, let me briefly introduce you to his work. He works on µRNA
simulations using a modified version of an algorithm that performs matches
between two sets: µRNA and genes (messaging RNA) from a cell line.
He developed a language that let one efficiently describe and execute
simulations. It does not have a name, but the whole thing is named Mirdesign,
“Mir” standing for µRNA.
The web application will become a showcase for his work by providing specific
testcases his language can actually describe. It consists of two layers:
an API written with Valum and backed by a worker pool, memcached, MySQL and
JSON documented here with Swagger
a client written with Semantic UI that consumes the API
As of now, we decided to go on with a HIV testcase that would let one select
a cell line, the amount of µRNA to pour and some extra genes that could be
specified or extracted from a FASTA file.
If it works well, other testcases will be implemented to cover yet unexplored
aspects of Mirdesign.
There’s still a couple of things to work out:
parsing the FASTA file (fasta will be used)
generating a Mirdesign word from user input
exposing (partially) the MySQL database through the web API
change the processing backend (TORQUE or other cluster)
I have been very busy in the last weeks so this update will cover the work of
three weeks instead of a typical bi-weekly update.
There’s no release announcement as I have been working on the assignment I have
to realize with the framework and steadily worked toward the 0.2.0-beta
release.
Alongside, I have been working on feature for the 0.3 serie which will
introduce middlewares. I have prototyped the following:
HTTP authentication (basic and digest)
content negociation
static resources
I have also introduced then in Route, which is a really handy feature to
create handling sequences and implemented the trailer from the chunked
encoding.
Update from Colomban!
I had an unexpected update from the developer of CTPL, Colomban Wendling. We
have talked a few weeks ago about the possibilities of having GObject
Introspection into the library so that we could generate decent bindings for
Vala.
He’s got something working and I will try to keep a good eye on the work so
that we can eventually ship a better binding for the templating engine.
CTPL is a good short-term solution for templating and if the library evolves
and integrates new features, it could possibly be a replacement for a possible
Mustache implementation.
The two big issues with CTPL is the lack of basic features:
filters
mapping
array of array
Filters let one attach a function to the environment so that it can be applied
on the variables instead of pre-processing the data.
Mappings could be easily implemented if Ctpl.Environ would be allowed to
contain themselves.
Containers are limited to hold scalars of the same type, which is quite
restrictive and prevents many usages.
Working prototype
I have a working prototype for the assignment that I will briefly describe
here.
In order to expose the algorithm developed by Nicolas Scott for his Ph. D
thesis, I decided to describe a RESTful API with the following endpoints:
PUT /task
GET /task/{uuid}
DELETE /task/{uuid}
GET /task/{uuid}/results
GET /tasks
GET /statistics
The task is still a very generic concept as I do not know much about what kind
of data will be poured into the program.
client submits a task with its data
the task is created (stored in memcached) and then queued in a ThreadPool
the pool eventually process the task in a worker thread
client requests the results of the task and either one of the following
scenario occurs:
the task is queued or processing and a 4xx is thrown
the task is completed and the result is transmitted
I have finished bindings for libmemcachedutil, which provides a connection
pool which has roughly doubled the throughput.
There’s still a few things to do:
GLib.MainLoop integration for libmemcached bindings to let the loop
schedule request processing and memcached operations
Semantic UI has nice API mapping capabilities that will be very useful to
present the data interactively.
The project will be containerized and shipped probably on Google Compute
Engine as it supports Docker.
Then…
This feature is really handy as it is common to reuse the matching process for
a sequence of handling callbacks. I will be introduced in the 0.3 branch as
it will work nicely along middlewares.
This feature was missing from the last release and solves the issue of calling
next when performing asynchronous operations.
When an async function is called, the callback that will process its result
does not execute in the routing context and, consequently, does not benefit
from any form of status handling.
app.get("",(req,res,next)=>{res.body.write_async("Hello world!".data,()=>{next();// if next throws anything, it's lost});});
What invoke brings is the possibility to invoke a NextCallback in the
context of any Router, typically the current one.
It respects the HandlerCallback delegate and can thus be used as a handling
middleware with the interesting property of providing an execution context for
any pair of Request and Response.
The following example will redirect the client as if the redirection was thrown
from the API router, which might possibly handle redirection in a particular
manner.
app.get("api",(req,res)=>{// redirect old api callsapi.invoke(req,res,()=>{thrownewRedirection("http://api.example.com");})});
As we can see, it offers the possibility of executing any NextCallback in any
routing context that we might need and reuse behiaviours instead of
reimplementing them.
RPM packaging
I wrote a specfile for RPM packaging so that we can distribute the framework on
RPM-based distributions like Fedora and openSUSE. The idea is to eventually
offer the possibility to install Valum in a Docker
container to facilitate the deployment of web services and applications.
I have literally no knowledge about Debian packaging, so if you would like to
give me some help on that, I would appreciate.
The past week were higly productive and I managed to release the 0.2.0-alpha
with a very nice set of features.
There are 38 commits separating v0.1.4-alpha and v0.2.0-alpha tags and they
contain a lot of work.
Click the arrow to see the 38 commits descriptions.
1f9f7da Version bump to 0.2.0-alpha.
0ecbf22 Fixes 9 warnings for the VSGI implementations.
64df1f5 Test for the ChunkedConverter.
cc9f320 Fixes libsoup-2.4 (<2.50) output stream operations.
de27c7b Renames Server.application for Server.handle.
f302255 Improvments for the documentation.
c6587a0 Removes reference to connection in Response.
5232c48 Write the head when a status is handled to avoid an empty message.
61961ee Fixes the code formatting for the handling process.
05aca66 Improves the documentation about asynchronous processing.
41ce7a7 Removes timeout as it is not usable with the processing model.
42bbfc7 Updates waf to 1.8.11 and uses the valac threading fix.
7588cf2 Exposes head_written as a property in Response.
4754131 Merge branch '0.2/redesign-async-model'
409e920 Updates the documentation with 0.2/* changes.
acf6200 Explicitly closes with async operations.
22d8c54 Provides SimpleIOStream for gio-2.0 (<2.44).
eeaeee1 Considers 0-sized chunk as ending chunk in ChunkedConverter.
86b0752 Provides write_head and write_head_async to write status line and headers.
11e3a34 Uses reference counting to free a request resources.
19dc0e2 Replaces VSGI.Application with a delegate.
53e6f24 Ignores the HTTP query in 'REQUEST_URI' environment variable.
5596323 Improves testability of FastCGI implementation and provide basic tests.
fb6b0c4 FastCGI streams uses polling to perform read and write operations.
3ec5a22 Tests for the libsoup-2.4 implementation of VSGI.
869fe00 Fixes 2 compilation warnings.
dfc98e4 Adds a transparent gzip compression example using ZLibCompressor.
79f9b18 Write request http_version in response status line.
937ceb2 Avoid relying on states to write status line and headers.
e73ebd6 Properly close the request and response body in end default handler.
fc57bf0 Documentation for converters.
384fd97 Reimplements chunked streams with a Converter.
c7c718c Renames raw_body of base_stream in Response.
0479739 steal_connection is available with libsoup-2.4 (>=2.50)
2a25d8d Set Transfer-Encoding for chunked in Router setup with HTTP/1.1.
c8ebad7 Writes status line and headers in end if it's not already done.
1678cb1 Uses ChunkedOutputStream by default in Response base implementation.
bb10337 Uses real stream by VSGI implementations.
Some of these commits were introduced prior to the seventh week update, the
exact date can be checked from GitHub.
steal the connection for libsoup-2.4 implementation
write_head and write_head_async
head_written property to check if the status line and headers has been
written in the response
I am working toward a stable release with that serie, the following releases
will bring features around a solid core in a backward-compatible manner.
Three key points for what’s coming next:
middlewares
components
documentation
distribution (RPM, Debian, …)
deployment (Docker, Heroku, …)
Finishing the APIs
All the features are there, but I really want to take some time to clean the
APIs, especially ensuring that naming is correct to make a nice stable release.
I have also seeked feedback on Vala mailing list, so that I can get some
reviews on the current code.
Asserting backward compatibility
Eventually, the 0.2.0 will be released and marked stable. At this point, we
will have a considerable testsuite that can be used against following releases.
According to semantic versionning (the releasing model we
follow), any hoftix or minor releases has to guarantee backward-compatibility
and it can easily be verified by running the testsuite from the preceeding
release against the new one.
Once we will have an initial stable release, it would be great to setup a hook
to run the older suites in the CI.
What’s next?
There is a lot of work in order to make Valum complete and I might not be done
by the summer. However, I can get it production-grade and usable for sure.
CGI and SCGI implementations are already working and I will integrate them in
the 0.3.0 along with some middlewares.
Middlewares are these little piece of processing that makes routing fun and
they were thouroughly described in the past posts. The following features will
make a really good start:
content negociation
internationalization (extract the domain from a request)
authentication (basic, digest, OAuth)
cache (E-Tag, Last-Modified, …)
static resource serving from File or Resource
jsonify GObject
They will be gradually implemented in minor releases, but first they must be
thought out as there won’t be no going-backs.
I plan to work a lot on optimizing the current code a step further by passing
it in Valgrind and identify the CPU, memory and I/O bottlenecks. The
improvments can be released in hotfixes.
Valum will be distributed on two popular Linux distributions at first: Ubuntu
and Fedora. I personally use Fedora and it would be a really great platform for
that purpose as it ships very innovative open source software.
Once distributed, it will be possible to install the software package in
a container like Docker or a hosting service like Heroku and make development
a pleasing process and large-scale deployment possible.
Tomorrow, I will be releasing the first version of the 0.2 serie of Valum web
micro-framework.
There’s still a couple of tests to make to ensure that everything is working
perfectly and I will distribute the 0.2.0-alpha.
This serie will target an eventually stable release after which rules will be
enforced to ensure API compatibility. It will definately mark the end of the
last days prototyping.
I am happy to announce the release of a 0.1.4-alpha version of Valum web
micro-framework that bring minor improvments and complete CLI options for
VSGI.Soup.
Cookies
The cookies were moved from VSGI to Valum since it’s only an abstraction over
request and response headers. VSGI aims to be a minimal protocol and should
provide just enough abstraction for the HTTP stack.
CLI options for VSGI.Soup
This is quite of a change and brings a wide range of new possibilities with the
libsoup-2.4 implementation. It pretty much exposes Soup.Server
capabilities through CLI arguments.
In short, it is now possible to:
listen to IPv4 or IPv6 only
listen from a file descriptor
liste from all network interfaces (instead of locally) with --all
enable HTTPS and specify a certificate and a key
set the Server header with --server-header
prevent Request-URI from being url-decoded with --raw-paths
The implementation used to listen from all interfaces, but this is not
a desired behiaviour. The --all flag will let the server listen on all
interfaces.
The behiaviour for --timeout has been fixed and now relies on the presence of
the flag to enable a timeout instead of a non-zero value. This brings the
possibility to set a timeout of value of 0.
There is some potential work for supporting arbitrary socket, but it would
require a new dependency gio-unix that would only support UNIX-like systems.
Since the 0.1.0-alpha release, I have been releasing a bugfix release every
week and the APIs are continuously stabilizing.
I have released 0.1.2-alpha with a couple of bugfixes, status code handlers
and support for null as a rule.
I have also released a 0.1.3-alpha
that brought bugfixes and the possibility to pass a state in next.
Along with the work on the current releases, I have been working on finishing
the asynchronous processing model and developed prototypes for both CGI and
SCGI protocols.
Passing a state!
It is now possible to transmit a state when invoking the next continuation so
that the next handler can take it into consideration for producing its
response.
The HandlerCallback and NextCallback were modified in a backward-compatible
way so that they would propagate the state represented by a Value?.
The main advantage of using Value? is that it can transparently hold any type
from the GObject type system and primitives.
This feature becomes handy for various use cases:
pass a filtered stream over the response body for the next handler
compute and transmit in separate handlers
the computation handler is defined once and pass the result in next
different handlers for transmitting different formats (JSON, XML, HTML, plain text, …)
fetch data common to a set of routes
build a component like a session or a model from the request and pass it to
the next route
This example shows how a state can be passed to conveniently split the
processing in multiple middlewares and obtain a more modular application.
app.scope("user/<int:id>",(user)=>{// fetch the user in a generic mannerapp.all(null,(req,res,next)=>{varuser=newUser.from_id(req.params["id"]);if(user.loaded())thrownewClientError.NOT_FOUND("User with id %s does not exist.".printf(req.params["id"]));next(user);});// GET /user/{id}/app.get("",(req,res,next,state)=>{Useruser=state;next(user.username);});// render an arbitrary JSON objectapp.all(null,(req,res,next,state)=>{vargenerator=newJson.Generator();// generate compacted JSONgenerator.pretty=false;generator.set_root(state);generator.to_stream(res.body);});})
It can also be used to build a component like a Session from the request
cookies and pass it.
app.all(null,(req,res,next)=>{for(varcookieinreq.cookies)if(cookie.name=="session"){next(newSession.from_id(cookie.value));return;}varsession=newSession();// create a session cookieres.cookies.append(newCookie("session",session.id));});
This feature will integrate very nicely with content negociation middlewares
that will be incorporated in a near future. It will help solving typical case
where a handler produce a data and other handlers worry about its transmission
in a desired format.
app.get("some_data",(req,res,next)=>{next("I am a state!");});app.matcher(accept("application/json"),(req,res,next,state)=>{// produce a json responseres.write("{\"message\": \"%s\"}".printf(state.get_string()));});app.matcher(accept("application/xml"),(req,res,next,state)=>{// produce a xml responseres.write("<message>%s</message>".printf(state.get_string()))});
This new feature made it into the 0.1.3-alpha release.
Toward a minor release!
I have been delayed by a bug when I introduced the end continuation to
perform request teardown and I hope I can solve it by friday. To avoid blocking
the development, I have been introducing changes in the master branch and
rebased the 0.2/* upon them.
The 0.2.0-alpha will introduce very important changes that will define the
asynchronous processing model we want for Valum:
write the response status line and headers asynchronously
end continuation invoked in synchronous or asynchronous contexts
assign the bodies to filter or redirect them
lower-level libsoup-2.4 implementation that takes advantage of non-blocking
stream operations
polling for FastCGI to perform non-blocking operations
Most of these changes have been implemented and will require tests to ensure
their correctness.
Some design changes have pushed the development a bit forward as I think that
the request teardown can be better implemented with reference counting.
Two major changes improved the processing:
the state of a request is not wrapped in a connection, which is typically
implemented by an IOStream
the request and response hold the connection, so whenever both are out of
scope, the connection is freed and the resources are released
Not all implementation provide an IOStream, but it can easily be implemented
and used to free any resources in its destructor.
I hope this can make it in the trunk by friday, just in time for the lab
meeting.
New implementation prototypes
I have been working on CGI and SCGI prototypes as these are two very important
protocols for the future of VSGI.
CGI implements the basic CGI specification
which is reused in protocols like FastCGI and SCGI. The great thing is that
they can use inheritence to reuse behiaviours from CGI like the environment
extraction to avoid code duplication.
In order to keep a clean history of changes, we use a rebasing model for the
development of Valum.
The development often branches when features are too prototypical to be part of
the trunk, so we use branch to maintain these different states.
Some branches are making a distinct division in the development like those
maintaining a specific minor release.
master
0.1/*
0.2/*
…
They are public and meant to be merged when the time seems appropriate.
At some point of the development, we will want to merge 0.2/* work into the
master branch, so the merge is a coherent approach.
When rebasing?
However, there’s those branches that focus on a particular feature that does
not consist of a release by themselves. Typically, a single developer will
focus on bringing the changes, propose them in a pull request and adapt them
with others reviews.
It is absolutely correct to push --force on these submissions as it is
assumed that the author has authority on the matter and it would be silly for
someone else to build anything from a work in progress.
If changes have to be brought, amending and rewritting history is recommended.
If changes are brought on the base branch, rebasing the pull request is also
recommended to keep things clean.
The moment everyone seems satisfied with the changes, it gets merged. GitHub
creates a merge commit even when fast-forwarding, but it’s okay considering
that we are literally merging and it has the right semantic.
Let’s just take a typical example were we have two branches:
master, the base branch
0.1/route-with-callback, a branch containing a feature
Initially, we got the following commit sequence:
master
master -> route-with-callback
If a hotfix is brought into master, 0.1/route-with-callback will diverge from
master by one commit:
master -> hotfix
master -> route-with-callback
Rebasing is appropriate and the history will be turned into:
master -> hotfix -> route-with-callback
When the feature’s ready, the master branch can be fast-forwarded with the
feature. We get that clean, linear and comprehensible history.
How do I do that?
Rebasing is still a cloudy git command and can lead to serious issues from
a newcomer to the tool.
The general rule would be to strictly rebase from a non-public commit. If
you rebase, chances are that the sequence of commits will not match others, so
making sure that your history is not of public authority is a good starter.
git rebase -i is what I use the most. It’s the interactive mode of the rebase
command and can be used to rewrite the history.
When invoked, you get the rebasing sequence and the ability to process each
commit individually:
squash will meld two commits
fixup is like squash, but will discard the squashed commit message
reword will prompt you for editing the commit message
I often stack work in progress in my local history because I find it easier to
manage than stashes. When I introduce new changes on my prototypes, I fixup the
appropriate commit.
However, you can keep a cleaner work environment and branch & rebase around,
it’s as appropriate. You should do what you feel the best with to keep things
manageable.
Valum 0.1.1-alpha has been released, the changeset is described in the
fifth week update I published
yesterday.
You can read the release notes
on GitHub to get a better idea of the changeset.
I am really proud of announcing that release as it bring two really nice
features:
next continuation in the routing process
all and methods
These two features completely replace the need for a setup signal. It’s only
a matter of time before teardown disappear with the end continuation and
status handling that the 0.2.0-alpha release will bring.
I expect the framework to start stabilizing on the 0.2.* branch when the
asynchronous processing model will be well defined and VSGI more solid.
These past two weeks, I have bee working on a new release 0.2.0-alpha and
fixed a couple of bugs in the last release.
To make thing simple, this report will cover what have been introduced in
0.1.1-alpha and 0.2.0-alpha releases separately.
The 0.2.0-alpha should be released by the fifth of june (05/05/15) and will
introduce the so awaited asynchronous processing model.
As of right now
I have fixed a couple of bugs, backported minor changes from the 0.2.0-alpha
and introduced minor features for the 0.1.1-alpha release.
Here’s the changelog:
e66277c Route must own a reference to the handler.
ec89bef Merge pull request #85 from valum-framework/0.1/methods
b867548 Documents all and methods for the Router.
42ecd2f Binding a callback to multiple HTTP methods.
e81d4d3 Documents how errors are handled with the next continuation.
5dd296e Example using the next continuation.
ec16ea7 Throws a ClientError.NOT_FOUND in process_routing.
fb04688 Introduces Next in Router.
79d6ef5 Support HTTPS URI scheme for FastCGI.
29ce894 Uses a synchronous request processing model for now.
e105d00 Configure option to enable threading.
5f8bf4f Request provide HTTPVersion information.
0b78178 Exposes more GObject properties for VSGI.
33e0864 Renames View splice function for stream.
3c0599c Fixes a potential async bug with Soup implementation.
91bba60 Server documentation.
It is not possible to access the HTTP version in the Request, providing useful
information about available features.
FastCGI implementation honors the URI scheme if it sets the HTTPS environment
variable. This way, it is possible to determine if the request was secured with
SSL.
I enforced a synchronous processing model for the 0.1.* branch since it’s not
ready yet.
It is now possible to keep routing if we decide that a handler does not
complete the user request processing. The next continuation is crafted to
continue routing from any point in the route queue. It will also propagate
Redirection, ClientError and ServerError up the stack.
Processing asynchronously has a cost, because it delegates the work in an event
loop that awaits events from I/O.
The synchronous version will execute faster, but it will not scale well with
multiple requests and significant blocking. The asynchronous model will
outperform this easily due to a pipeline effect.
VSGI improvments
Request and Response now have a base_stream and expose a body that may
filter what’s being written in the base_stream. The libsoup-2.4
implementation uses that capability to perform chunked transfer encoding.
There is no more inheritence from InputStream or OutputStream, but this can
be reimplemented using FilterInputStream and FilterOutputStream.
I have implemented a ChunkedConverter to convert data into chunks of data
according to RFC2126 section 3.6.1.
It can also be used to do transparent gzip compression using the
ZlibCompressor.
Soup reimplementation
The initial implementation was pretty much a prototype wrapping a MessageBody
with an OutputStream interface. It is however possible to steal the connection
and obtain an IOStream that can be exposed.
MessageBody would usually worry about transfer encoding, but since we are
working with the raw streams, some work will have to be done in order to
provide that encoding capability.
In HTTP, transfer encoding determines how the message body will be
transmitted to its recipient. It provides information to the client about
what amount of data will be transfeered.
Two possible transfeer encoding exist:
use the Content-Length header, the recipient expects to receive that number of bytes
use chunked in Transfer-Encoding header, the recipient expects to receive a chunk size followed by the content of the chunk
TCP guarantees the order of packets and thus, the order of the received chunks.
I implemented an OutputStream capable of encoding written data according to
the header of the response. It can be composed with other streams from the GIO
api, which is more flexible than a MessageBody.
The response exposes two streams:
output_stream, the raw and protected stream
body, the public and safe for transporting the message body
Some implementations (CGI, FastCGI, etc…) delegate the transfer encoding
responsbiility to the HTTP server.
Status handling
The setup and teardown approach have been deprecated in favour of next
continuation and status handling.
Handler can be connected to status thrown during the processing of a request.
If a status handler throws a status, it will be captured by the Router. This
can be used to cancel the effect of a redirection for instance.
Likewise, status handling can invoke end to end the request processing and
next to delegate the work to the next status handler in the queue.
In the past two weeks, I’ve been working on the roadmap for the 0.1.0-alpha
release.
gcov
gcov has been fully integrated to measure code coverage with
cpp-coveralls. gcov works by
injecting code during the compilation with gcc.
You can see the coverage on coveralls.io,
it’s updated automatically during the CI build.
Current master branch coverage:
The inconvenient is that since coveralls measures coverage from C sources using
valac generated C code, it is not possible to identify which regions are
covered in Vala. However, it is still possible to identify these regions in the
generated code.
Asynchronous handling of requests
I changed the request handling model to be fully asynchronous.
VSGI.Application handler have become an async function, which means that
every user request will be processed concurrently as the server can immediatly
accept a new request.
Merged glib-application-integration in the trunk
The branch was sufficiently mature to be merged in the trunk.
I will only work on coverage and minor improvements until I reach the second
alpha release.
It brings many improvements:
VSGI.Server inherit from GLib.Application, providing enhancements described in
the Roadmap for 0.1.0-alpha
setup and teardown in the Router for pre and post processing of requests
user documentation improvments (Sphinx + general rewrites)
optional features based on gio-2.0 and libsoup-2.4 versions
0.1.0-alpha released!
I have released a 0.1.0-alpha version. For more information, you can read the
release notes on GitHub,
download it and try it out!
Integration of GLib.Application is really cool. It basically provide any
written application with a GLib.MainLoop to process asynchronous tasks and
signals to handle startup and shutdown events right from the Server.
usingValum;usingVSGI.Soup;varapp=newRouter();varserver=newServer(app);// unique identifier for your applicationapp.set_application_id("your.unique.application.id");app.get("",(req,res)=>{res.write("Hello world!".data);});server.startup.connect(()=>{// no request have been processed yet// initialize services here (eg. database, memcached, ...)});server.shutdown.connect(()=>{// called after the mainloop finished// all requests have been processed});server.run();
Moreover, application can access a DBusConnection and obtain environment data
or request external services.
This sample uses the org.freedesktop.hostname DBus service to obtain
information about the hosting environment. Note that you can use DBus to
perform IPC between workers
fairly easily in Vala.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
varconnection=server.get_dbus_connection();app.get("hostname",(req,res)=>{// asynchronous dbus callconnection.call.begin("org.freedesktop.hostname",// bus name"/org/freedesktop/hostname",// object path"org.freedesktop.hostname",// interface"Hostname",null,// no argumentsVariantType.STRING,// return typeDBusCallFlags.NONE,-1,// timeoutnull,(obj,r)=>{varhostname=connection.call.end(r);res.write(hostname.get_string().data);});});
GLib.Application are designed to be held and released so that it can quit
automatically whenever it’s idle (with a possible timout). Gtk uses it to count
the number of opened windows, we use it to measure the number of processing
requests.
Past a certain timeout after the last release, the worker will terminate.
If you have a long-running operation to process asynchronously that does not
involve writting the response (in which case, you are better blocking), you
have to hold the application to keep it alive while it’s processing.
What next?
The next release will be more substantial:
middlewares
components (if relevant)
improve VSGI specification
more signals to handle external events
better documentation to guide implementations
new VSGI implementations (SCGI & CGI)
extract VSGI (if ready)
I decided to go ahead for a Mustache implementation that targets GLib and
GObject. I’m still surprised that it hasn’t been done yet. It is clearly
essential to bring Vala in general purpose web development. The development
will be in a separate project here on
GitHub and it will not block
the release of the framework.
GResource API is really great and it would be truly amazing to bundle Mustache
templates like we already do with CTPL.
As part of the first week, I have to produce an initial document describing what
I will be working on during the semester. Once it’s written down, I will post it
on this blog.
I have already a good idea of what I would like to work on:
finish VSGI specification
second alpha release & feedback from communities
SCGI implementation
mustache implementation for GLib
more tests and awesomeness
The first alpha release is already 4 years old and this one bring such radical
changes that we’re almost starting over. Therefore, a second alpha release will
permit us to tease the targeted audience and obtain recommendations to build the
very best framework.
SCGI is a very
simple protocol to communicate HTTP messages over streams. It will take a real
advantage of the GIO stream API and
I am sure this could become an efficient way to serve web application in
production.
Mustache (or any templating engine) is essential
if we want to bring Valum outside the web service development. I plan to
provide a GLib implementation so that it can be used anywhere. CTPL will remain
the default templating engine for its simplicity and convenience as it covers
quite well simple UI requirements.
Testing is part of any sane software development process. I will focus on
providing quality software that does not break easily.
Subsequent weeks will contain more sustained posts that will describe what have
been done, so stay put!
I will officially work on Valum this summer under the direction of
François Major
at the IRIC lab.
As part of the evaluation, I will be have the opportunity to demonstrate the
framework potential with an assignment. Also, I am required to keep track of
the project advancements, so keep in touch with the Valum category of
my blog!

{kind=link}
{kind=link}